戻る
目次
|
その1 最初の話
その2 カタチをきれいに並べてみたい その3 とりあえず並べてみる その4 G.D.Birkhoffの審美測度 その5 離散的構造の不変量 その6 そもそも色鉛筆は並ぶのか? その7 複雑さでもう少し… |
カタチの並べ替え
その1 最初の話
ふたりの子供がもめている。聞いてみれば、どちらの形の方がセンスがいいか、という。別に競うものでもなかろうにとは思ったが、そういうのはまんざら嫌いでもないので見てみた。

どうやら馬と鹿らしい。なんだ、違うものじゃしょうがないじゃないか。しかしそんなことは問題ではないという。まあそうかも知れない。よく見ればふたつの形は似た所が多い。ただ好き嫌いで決めるにしてもこれは一目では決めかねる。どうしたものか。
とりあえずセンスはこっちに置いといて、どちらが凝った形かで決めよう。面積は同じ…そりゃそうだ。頂点の数は…19個、こっちも19個か。じゃあ周の長さは?えーと22.3cmと、23.4cm。鹿の方が長いな、じゃ鹿の勝ち。………あ、納得してないよ。
その2 カタチをきれいに並べてみたい
どちらの形が良いかというのは、さすがにどうとも言えませんが、シルエットをたくさん並べたときに、順番によってかなり印象は変わるように思います。別に心理学上どうのという話ではなくて、色鉛筆を並べるみたいに、新しく作ったシルエットを、昔の人が作ってきた厖大なシルエットの中に、うまい順序でマッピングしてくれるものがあれば、ちょっと面白いかなあ、と思ったわけです。
その3 とりあえず並べてみる
easy Tangram editorには、〝ニュアンスでソート〟という謎の機能が付いていますが、これは一応シルエットをカタチで並べ替える機能です。
並べ替えの原理としては、まず背景画素を-1、シルエットの画素を1として隣り合う画素どうしで掛け算し、それを画像全体に渡って足し合わせます。その値をシルエットの間で比較して、並べ替えを行います。これはほとんど、輪郭の画素数で比べているのと同じことになります。シルエットそのものの面積は同じなので、単純に周の長さが長ければ、込み入った図形だろうと考えたわけです。
この方法で並べたところを一部ご紹介しましょう。まあまあ、それなりに並んでいるような気はしますね。しかし、似た形がいまいち近くにいなかったりと、まだまだ不満は残ります。


その4 G.D.Birkhoffの審美測度‐Aethetic Measure ‐
図形に主観的な序列をつける試みとしては、バーコフの審美測度が、先鞭的な意味で有名です。バーコフ(George David Birkhoff 1884-1944)は20世紀初頭のに活躍したアメリカの数学者ですが、エルゴートの定理など、物理方面でも名の知れた人です。Aethetic Measure (1933)は、彼が晩年に手がけた仕事のひとつでした。
Aethetic Measure では、好ましさの測度をM として、秩序の程度O と複雑さC の比O/C で表そうとしています。特に、O はわかりにくい量ですが、多角形の場合には、垂直対称性、回転対称性、平衡性、水平垂直網の関連性、不満足さ、といったものを足し合わせて作るのだそうです。この審美測度が決定的でないことは想像に難くありませんが、複雑さが好ましさにマイナスになる、といった発想などは、図形を評価する一つ態度として、非常に参考になるような気がします。
その5 Invariants for Discrete Structures(離散的構造の不変量)
最近の論文で、タングラムのシルエットを分類する実験が載っているものを見つけました。Hans Burkhardtさん、Marco Reisertさん、Hongdong Liさんの共著、Freiburg大学LMB内のページ(下のリンク)などからPDFを見ることができます。
この論文の趣旨は、タングラムを分類することではなくて、表題のとおり、連続でない構造が持つ不変量を提示することです。内容をごく表面的に書き留めると、まず離散的に分布する点の連結で構成されるオブジェクトの不変量を、Diracのデルタ関数を組み込みこんだ変換の核となる関数のHaar積分で表現します。最終的に不変量は核となる関数そのものの形となり、計算要素(という言い方が良いかどうか…)として、近隣の点との距離による単項式を採用します。その有効性を、タングラムのシルエットを分類することで試しています。
私はLebesgue積分が解っていないので、内容が本当に理解できているとは言えないのですが、最終的に行う計算そのものはすっきりしていて、ちょっと感動します。
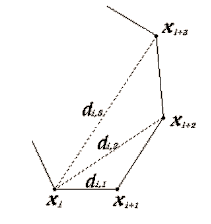
|
まず、シルエットの頂点がN個あったとして、その頂点の座標を順番にx 0, x 1, … , x N - 1 とします。そして、x i と x < i + k > の距離を d i , k ≡ || x i - x < i + k > || と書くことにします。なお < i + k > というのは、i + k を N で割った余りです。d i , k を図で描くと左のような感じになります。
論文の実験では4つ離れた点までの距離を使って、特徴量(不変量) x~ n1, n2, n3, n4≡ Σi di,1n1 di,2n2 di,3n3 di,4n4 を定義し、一つのシルエットについて以下の14個の特徴量を計算しています。 |
x~
1, 0, 0, 0
x~
0, 1, 0, 0
x~
0, 0, 1, 0
x~
1, 1, 0, 0
x~
1, 0, 1, 0
x~
0, 1, 1, 0
x~
0, 0, 0, 1
x~
1, 0, 0, 1
x~
0, 1, 0, 1
x~
0, 0, 1, 1
x~
2, 0, 0, 0
x~
0, 2, 0, 0
x~
0, 0, 2, 0
x~
0, 0, 0, 2
この14個の数値の組が、一つのシルエットを特徴付ける量だということです。ちなみに、これらは、シルエットの移動・回転によって変わりません。これが不変量と言われる由縁でもあります。
この特徴量の検証のために、シルエットの頂点の位置に少しぶれを与えて、同じシルエットとして判定できるかどうか、といった実験が行われています。一つのシルエットは14個の特徴量を軸とする、14次元の特徴量空間の一点に対応します。シルエットに対応する点が近ければ、それだけ2つのシルエットは似ていることになる訳です。ただし、頂点の位置のぶれは等方的でも、特徴量空間に現れる影響は等方的とは限らないので、その異方的な分散を考慮したMahalanobis距離というものを計算します。特に似たようなシルエットが多い場合には、精度にけっこう影響があるそうです。
ところで、分類を並べ替えに置き換えると、どう考えられるでしょう。実は、シルエットの特徴をあらわす量が1つから2つに増えただけでも、もうどうやって並べ替えればいいのか、よく解らなくなってくることに気がつきます。まだいくつ変数が必要か判りませんが、いずれは考えないとだめそうです。
その6 そもそも色鉛筆は並ぶのか?
さて…。並べ替えは、2つのシルエットの順序が決まれば一番いいのですが、特徴を表す量がいくつもあったとしたら、一体どうやって順番を決めればいいでしょうか。そもそも、色鉛筆を並べるように、と言っても、色は3次元の量です。では色鉛筆を並べる、といのは実際には何をやっていたことになるのでしょう。ちょっと寄り道をして、色鉛筆を並べることを少し考えてみたいと思います。
折角なので、普段は指をくわえて眺めるだけのCaran d'Ache の水彩色鉛筆30色セットを見てみましょう。色の分布は下の図のような感じです。鮮やかな色ほど縁にあり、明るい色が手前、暗い色が奥にある、どこかで見たことあるようで似て非なる適当な色空間です。30色ではどういう空間なのかイメージが掴みづらいと思いますので、easy Tangram editorでも使わせていただいている、444色色見本ソフトの色を配置した図も載せておきます。
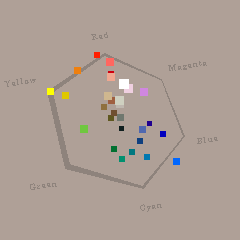 PRISMALO(®Caran d'Ach) 水彩色鉛筆30色セットより |
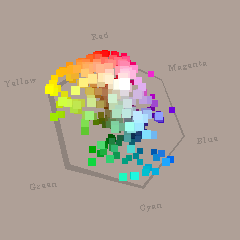 『 444色 色見本ソフト』より444色 (©どうとんさん) |
まずは、これらの色を画面に表示させるために使っている、光の3原色の値(RGB)を使って並べ替えることを企んでみます。ここは安直に白を出発点として、一番近い色(RGB空間上の距離 √(ΔR² + ΔG² + ΔB²) が一番小さくなる色)を次々に繋いでいきます。しかし、これだけではさすがに問題があって、必ずしも近所の色をもれなく拾い上げられないせいで、最後の方になって取りこぼした色に突然跳んだりします。
これを解決するには、一番近い色でなくても、今通っておけば全体的に無駄の少ないパスになるな、という判断ができればいい訳です。これはセールスマン巡回問題(TSP:traveling salesman problem)に似ています。今は別に同じ場所に戻ってくる必要はありませんが、それよりもずっと問題なのは、これがもの凄い計算量を要するということです。例えば始点と終点を固定したとして、残りの28色を全て通るルートは 28! ( = 28×27×…×2×1 ) ~ 3×10 29 通りほどあります。最近のPCが 3.0[GHz] = 3×10 9[Hz] で、1ルートのパスの長さが100クロックで計算できたとしても、 10 22秒 ~ 330兆年は余裕でかかります。なので、まともに計算するのは到底無理です。それでも計算したい場合には、最初に適当にパスを設定して、局所的に順番を入れ替えながら更に良いルートが無いかを探す、といった手法が現実には行われるそうです。
もう一つ、色と色の間の距離をRGB空間のEuclid距離 √(ΔR² + ΔG² + ΔB²) で計算してきましたが、これが感覚的な距離といつも合致するわけではなく(ペイントなどの色の作成シートで、色が急に変わるところがあったり、一方では妙に変化に乏しいところがあったりするのはそのせいです)、今回は直接問題となるので、距離がほぼそのまま感覚的な色の差となるような均等色空間に移し変えて考える事にします。色空間としては、今回はL*a*b*表色系なるものを使うことにします。ちなみに、L*a*b*表色系でも1つの色は3つの値(L*,a*,b*)で表されます。直感的には、L*は色の明るさ、-a*→a*は緑→赤、-b*→b*は青→黄を示す軸です。この変換が実はかなり面倒です。手順を一応書いておくと、もとのRGBから逆γ補正した線形RGBをXYZ表色系に変換して、それをさらにD65標準光源、視野角2°の条件でL*a*b*表色系に変換します。
結局のところ、RGB空間で近い点を繋げておおまかにパスを決めた後、L*a*b*空間で局所探索法という手法を使ってパスを修正します。そうして並べた結果、下のようになりました。
 その1. 色鉛筆並べ替えの図 |
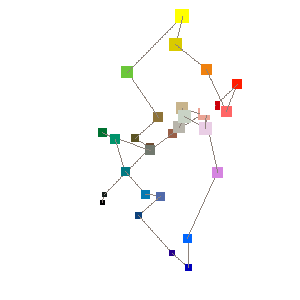 その2. L*a*b*空間での並べ替えのパス図 (遠近があるのでかなり判りにくいですが…) |
それなりに並んでいますよね?
しかし、これで気を良くして444色の並べ替えもやってみたところ、そちらはあまり上手くいきませんでした。どうも、短くても複雑に折り畳まれたパスだと反復が多く、あまり並んでいるという感じになりません。それと、TSPの近似解法は初期経路に振られることもあって、結局は最初の方針に左右されているようです。
あいかわらず問題は残りますが、パラメータがたった一つしかない場合も含めて、パラメータ空間で全ての要素を通る最適な(大体は最短の)パスを決めることが、並べ替えるということのような気がします。多次元の場合は、あらゆるスケールで最適なパスになっていることが、より理想に近いのかも知れません。
その7 複雑さでもう少し…
1つのシルエットからいろいろな観点で引き出した情報を使って一群のシルエットを並べ替えようとしたとき、シルエット一つひとつを辿っていく方法では、大局的に見ると、特に数が多い場合にはいまいちなのではないかと思い始めました。そこで、並べ替えについては自己組織化マップ(SOM:Self-Organizing Maps)を取り入れてみようと思います。自己組織化マップというのは、何か特徴に類似性のある情報が、情報の地図の中で自律的に寄り集まってクラスターを作る仕組みの数学的なモデルで、そもそもは頭、というか脳の中で起こっているそういった現象をモデル化する試みの一つですが、コンピュータとの相性もよく、データマイニングでは頼もしい存在です。
SOMの基本は非常にシンプルです。マップにn 個の節‐ノードがあるとして、i 番目のノードに情報m i を持たせます(紛らわしいですがm i は「モデル」と呼ばれます)。最初は、このm i はデタラメで構いません。次に、情報全体が張る空間の中からサンプルx を適当に一つ採ってきて、マップの中で一番距離の近いノードc を探します。距離の測り方はいろいろありますが、今はmi をベクトルと考えて、ユークリッド距離で測ることにします。このノードc と、位相的近傍の(c に番号の近い)ノードを、参照ベクトルx に近づけます。
hci は、どれだけmi をx に近づけるかを示していて、i がc に近いほど大きな値をとるようにします。mi を更新したら、また適当にx を選んできて…、というステップを何度も繰り返すうちに、情報空間の確立分布を反映した滑らかなマップが出来上がります。結局何どうなるのかをすぐにはイメージし難いかも知れませんが、ともかくこれで、似た情報を近くに配置しなおすためのマップができます。
さて、次はその肝心の情報はどうしましょう、という話です。以前、外郭画素数で並べ替えることをしていました。この尺度は思いのほか丈夫なので採用です。ただし、今回は複雑度として与えます。複雑度は輪郭線の長さの2乗を面積で割った値です。タングラムのシルエットの面積は一定なので、輪郭線の長さでも同じことなのですが、複雑度という尺度の方が感覚的に分かりやすいので、そうしておきます。さらに、シルエットをGaussianフィルターでぼかした時の複雑度も与えます。これは、シルエットを少し離れて見ているようなイメージです。ちなみに、複雑度はシフトや回転に不変な量なので、シルエットが縦長だとか横長という区別はできません。実際にはその辺ももう少し加味してほしいなあ、と思うので、縦横それぞれ領域を3等分して求めた面積のヒストグラムも与えることにします。これで情報は8次元のベクトルになりました。

 その1. 面積ヒストグラムと、ぼかしたシルエットの輪郭 |
8次元の図は描けないので、代表として複雑度とぼかした時の複雑度の断面を切り出したのが下の図です。マップのノード(100コ)の初期位置を点で示していて、位相上の隣り合うノードを線で結んであります。ノードの初期位置は、前に書いたようにデタラメです。あと、線で見づらくなっていますが、50コのシルエットの配置が記してあり、これらが参照ベクトルとして使われます。
 その2. 複雑度‐ぼかし複雑度断面 シルエットの配置(参照ベクトル)と、 初期マップノード |
上の図の状態から、シルエットをランダムに選び、それを参照ベクトルにしてマップを更新して行きます。hci はσ=4のGaussian分布に1-τ2(τはt を総ステップ数で割った無次元化時間)を掛けた関数です。ステップ数25,000回で収束したマップの例を、以下に紹介します。
 その3-a. 複雑度‐ぼかし複雑度断面のマップ 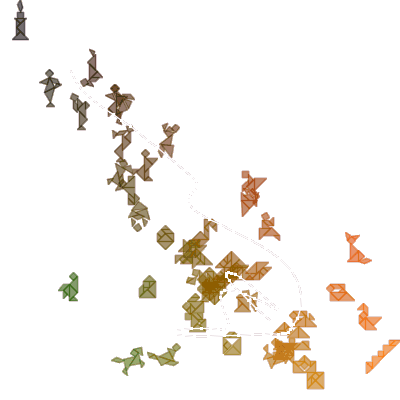 その3-b. 面積ヒストグラム左列‐中央列断面のマップ 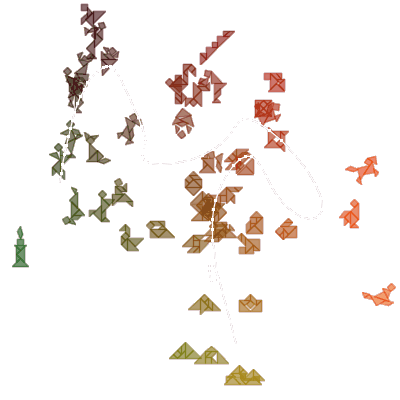 その3-c. 面積ヒストグラム右列‐上段断面のマップ  その3-d. 面積ヒストグラム中段‐下段断面のマップ |
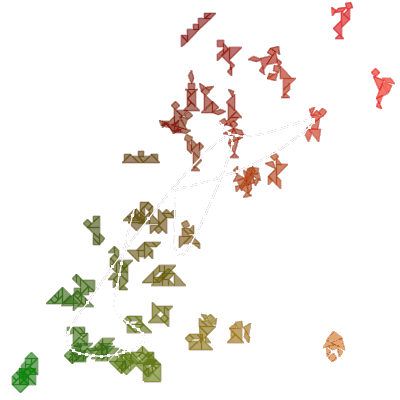
このマップを使って、シルエットを並べ替えます。それぞれのシルエットについて、まずどのノードに一番近いかを調べて、さらにその前後のどちらのノードにどれくらい寄っているかを求めておくと、シルエットを1列に並べることができます。こうして並べ替えた結果が、下の図になります。
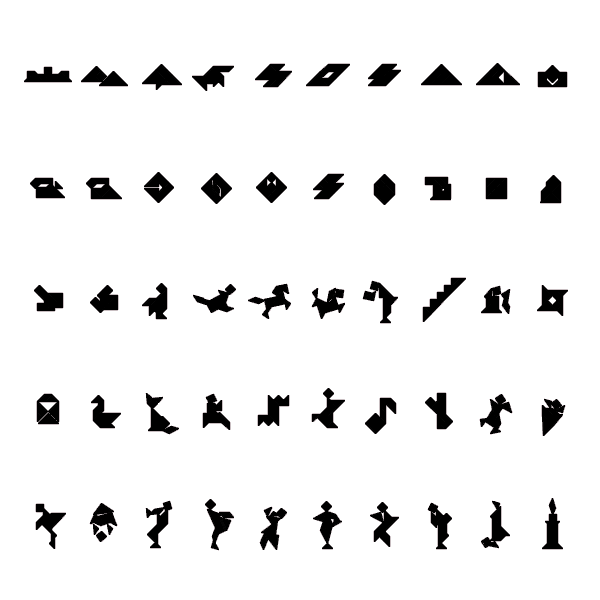 その4. 50個のシルエットを並べ替えたところ |
この結果はかなり揺らぎますが、カタチの広がりと複雑さの両面で並ぶ傾向は常に同じです。では、懸案のシルエットが多い場合はどうでしょう。古今東西より適当に集めた400コほどのシルエットについて、easy Tangram editorのように複雑度だけで並べた場合と、今回の8次元の特徴量からSOMを導入して並べ替えた場合で、結果は下のようになりました。
 その5-a. 複雑度だけで並べ替えた場合 |
 その5-b. SOMを導入して並べ替えた場合 |
感覚的に似た形が寄り集まるようになっていて、だいぶ当初思い描いていたイメージに近づいた気がします。
今回は所々「あーなるほど」という並び方をしていて、ちょっと楽しめます。もし自分の手で同じことをしようとしたら、純粋に作業として大変なだけでなくて、見立てを行ってしまうためにこういう並び方は思いつかないかも知れません。